地质构造的定量解释依赖于多参数模型(Multiparameter models,MPMs)的反演。传统方法是将模拟地震数据与观测地震数据匹配进行全波形反演(FWI),但由于多参数波动方程中隐含的参数间耦合关系(串扰问题),使得多参数 FWI 在拟合观测数据时比单参数(P 波速度)FWI 更不稳健且更病态;因此,多参数 FWI 的一项重要挑战是减弱参数间耦合以准确反演多参数模型。通常,减弱参数间耦合的方法包括采用分层策略通过序贯估计每一参数来最小化数据失配,或近似求解 Hessian 的逆以提供二阶信息来缓解串扰并同时估计所有参数。另一类方法是基于卷积神经网络的高分辨率反射波形反演(CNN-RWI),从初始速度模型和相应的偏移像预测地下速度模型。CNN-RWI 被归类为自监督深度学习,因为它从先验速度模型迭代地重建一小组速度模型作为伪标签,而无需像监督深度学习那样依赖大量高度代表性的速度模型。
基于监督深度学习的方法,需要大量标注样本但也无法精确预测多参数模型,因为用于标注的复杂合成多参数模型数量有限。为了解决这一问题,中国科学院地质与地球物理研究所博士后吴毓朗等提出了一种自监督多参数反演(Self-supervised multiparameter inversion,SS-MPI),将独立的 CNN 应用于从对应的初始多参数模型和偏移像预测多参数模型,实现从先验的基于早到时的层析成像和基于反射的偏移像中提供高分辨率的多参数模型。
SS-MPI 使用空间约束的分层 K-means 划分方法自动且自适应地从先验信息创建作为伪标签的多参数模型。然后,对真实的地球物理处理流程进行应用,以获得用于伪标签的先验信息(初始多参数模型及相应的偏移像)作为对应的训练输入数据。因此,SS-MPI 使得 CNN 能够基于训练数据集中从先验信息到伪标签的空间映射,从先验信息预测未知的真实多参数模型。接着,将 CNN 预测的多参数模型作为反馈,用于在下次迭代中自适应地重建训练数据集(伪标签及对应的先验信息),以递归的方式进行训练。
与传统多参数 FWI 通过匹配预测地震数据与观测地震数据来估计多参数模型不同,SS-MPI 通过自监督独立 CNN 更准确地预测未知的真实多参数模型。在 SS-MPI 中,地震数据有两种用途:其一用于生成最终作为网络输入进行模型预测的偏移图像;其二用于设定停止准则,通过判断数据失配是否达到最小值。因此,SS-MPI 在概念和实现上都较为简单。
弹性和各向异性模型的合成例子说明了 SS-MPI 的四个优点:(1)SS-MPI 缓解了模型参数之间的串扰问题,从而比传统的多参数 FWI(例如弹性 FWI)提供更高分辨率的多参数模型;(2)作为一种自监督深度学习方法,CNN 基于由先验信息逐步生成的更具代表性的多参数模型进行迭代训练,而不是基于与先验信息无关的、预先存在的随机多参数模型,先验信息有效地引导了训练多参数模型以及预测多参数模型的分布,使其朝向未知的真实多参数模型;(3)空间域的多参数模型(CNN 的输出)与空间域的先验信息(CNN 的输入)相对应,使得 CNN 能够逼近局部空间映射,该映射比从时域数据到空间域多参数模型的映射非线性程度要小;(4)SS-MPI 用自监督学习独立 CNN 来替代传统多参数 FWI中的数据拟合过程以解耦参数间关系,从而比传统的多参数 FWI 更准确地预测多参数模型。
图1 给出了自监督多参数反演(SS-MPI)框架的总体工作流程,包含两个主要分支:推理(图 1 上部)和训练(图 1 下部)。推理阶段包括三个关键步骤:地震数据采集、数据处理和基于 CNN 的预测。
在推理阶段(图 1 上部),使用非共享的 CNN 来利用由观测地震数据得到的逆时偏移(RTM)图像和初始多参数模型预测真实的多参数模型(MPMs),如 P 波速度(vp)和密度(ρ)。RTM 图像(Ix 和 Iz)作为所有 CNN 的共同输入提供,而每个初始参数模型(例如 P 波速度 vp 和密度 ρ)则作为单独专用的 CNN 的输入,用于各自参数的预测。
训练阶段(图 1 下部)也由三个类似步骤组成:正演模拟、数据处理和 CNN 训练。合成地震数据通过使用伪标签化的多参数模型作为真实模型进行正演建模来生成。随后这些数据以与真实数据相同的方式进行处理,所得的 RTM 像与初始多参数模型一起输入到非共享的 CNN 中。伪标签化的多参数模型是通过基于特征相似性对 CNN 预测的多参数模型进行划分并为每个分区赋予一个代表值而获得的。该过程使得 CNN 在无需真实模型监督的情况下进行训练,从而实现自监督学习。
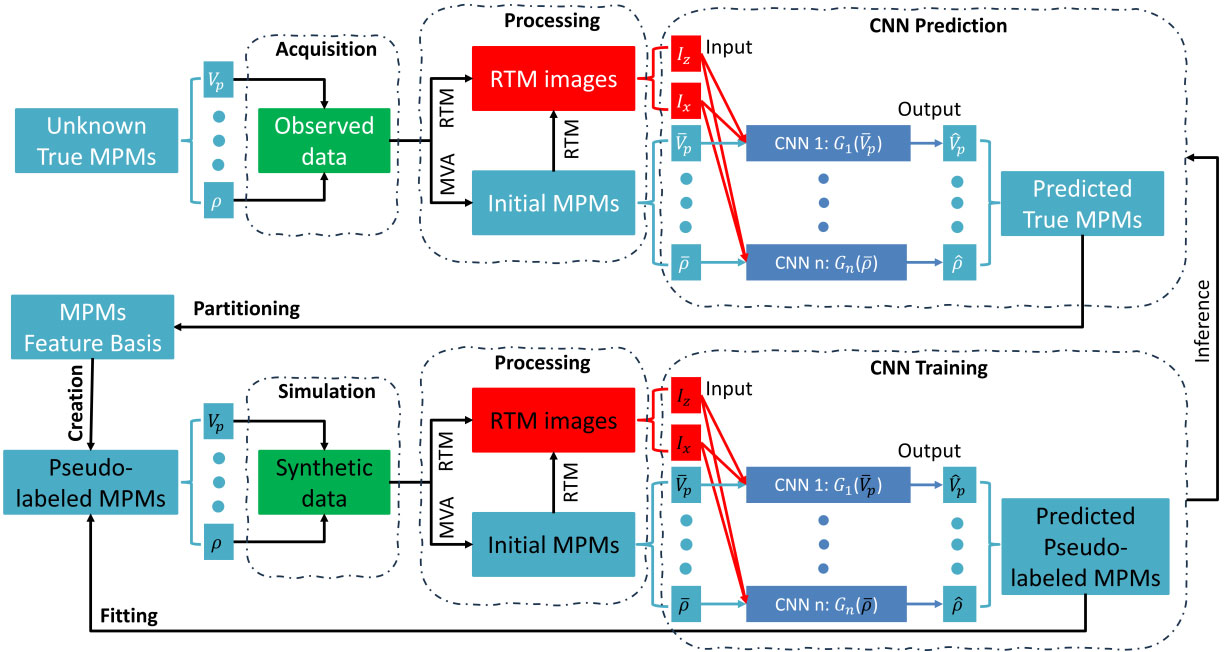
图1 自监督多参数反演(SS-MPI)框架的工作流程
在深度学习的迭代过程中,第一次迭代,伪标签化的多参数模型由真实地震数据处理得到的初始多参数模型进行划分而创建,因为未训练的 CNN 尚不能产生用于伪标签创建的物理上有意义的模型;第k次迭代,伪标签化的多参数模型由对上一次迭代中 CNN 预测的多参数模型进行划分而生成。尽管在每次迭代中(尤其是最初几次迭代)由划分初始多参数模型得到的伪标签化多参数模型与真实模型相去甚远,训练过程仍保持物理上的鲁棒性:数据生成过程采用高精度的正演建模,并通过高斯滤波近似和 RTM 步骤与应用于真实数据的处理一致(图2,图3)。因此,从真实多参数模型到其初始多参数模型及相应 RTM 像的映射在训练循环中得以一致保存。这种一致性使得 SS-MPI 成为一种物理引导的自监督方法,能够学习从初始多参数模型及对应的 RTM 像到未知真实多参数模型的有意义映射。

图2 均方根(RMS)对比:P波速度(a 列)、S波速度(b 列)、密度(c 列)和数据误差(d 列),对应图3中的弹性模型的合成结果。黑色和红色曲线分别表示 EFWI 和 SS‑MPI。青色点表示 SS‑MPI 中 32 个训练弹性模型在每次迭代时的均方根模型误差
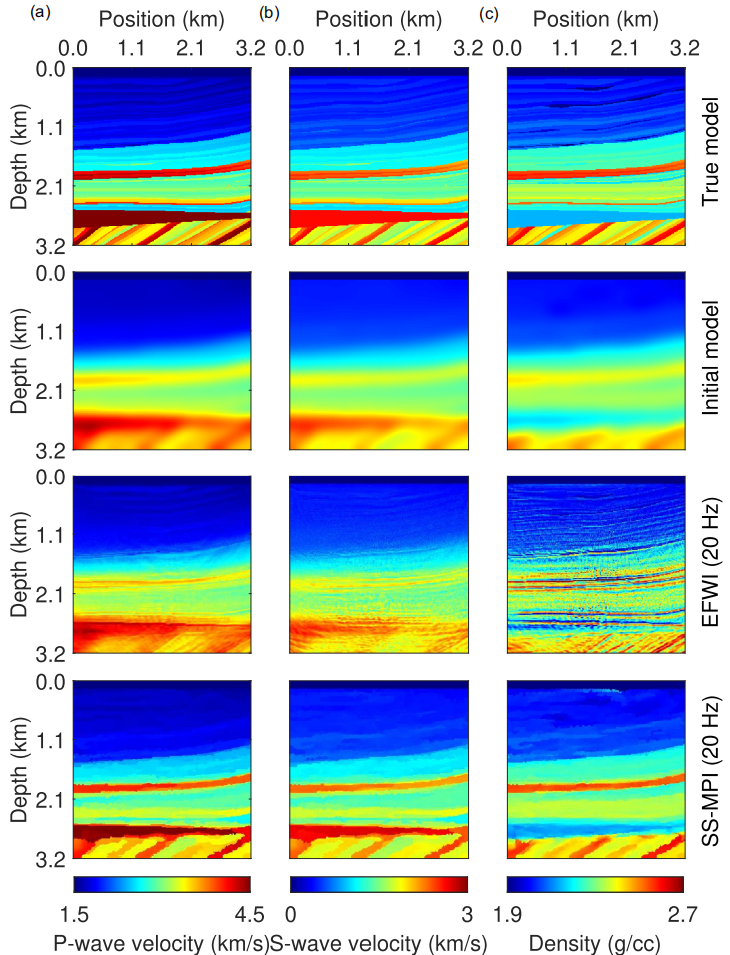
图3 弹性模型A的结果对比。a–c 列分别为 P 波速度、S 波速度和密度模型;第一行为真实的弹性模型 A;第二行为初始弹性模型 A,通过对第一行的真实模型连续应用 3×3 高斯滤波器 400 次得到;第三行和第四行分别为由 EFWI 和 SS‑MPI 反演得到的弹性模型 A
研究成果发表于国际学术期刊GJI(Wu Yulang,Wang Wenlong,Wang Yanfei,George A. McMechan. Deep learning-based self-supervised multiparameter inversion[J]. Geophysical Journal International,2025,243: 1-25. DOI: 10.1093/gji/ggaf332.)。研究受国家重点研发计划项目(2024YFA1012304)和国家自然科学基金项目(42450232,42374142)等资助。